
スキャン量を減らすためのBigQueryの工夫は、シャーディング、パーティショニング、そしてクラスタリングとあります。
ここではBigQueryの重要なポイントである、シャーディングと、パーティショニングについて説明します。
シャーディングとパーティショニングを行うのにテーブル設計は大事です。
ただBigQueryは従量課金と言って、通常のRDB代表格のMySQLのようにSQLを実行しても毎回無料ですが、BigQueryではSQLを実行するたびにスキャン量に応じて課金されます。
毎回データをフルスキャンして実行するとスキャン量も膨大になり、お金がかかってしまいます。
そこで、そのスキャン量を減らすための工夫として、シャーディングとパーティショニングがあります。
この機能についてここでは説明していこうと思います。
シャーディング
シャーディングとは、テーブルで同じ名前があったら、それを1つのテーブルにして表示する仕組みである。
BigQueryでは以下のようなテーブルがあれば、1つのテーブルにまとめてくれる習性があります。
同じデータセット内でtablename_YYYYMMDDというテーブル名の形式で作成すると、1つのテーブルでシャーディングを行います。
例えば以下のように、
table_name_20220101
table_name_20220102
と作成すると、table_name_(2)という表示でBigQuery上にテーブルが作成されます。(まとめられるという表現の方が正しいかも)
形式はなんでもいいというわけではなく、
table_name_1
table_name_2
や
table_name_a
table_name_b
とした時、それぞれtable_name_(2)という表示で作成されず、それぞれ別テーブルとして作成されます。
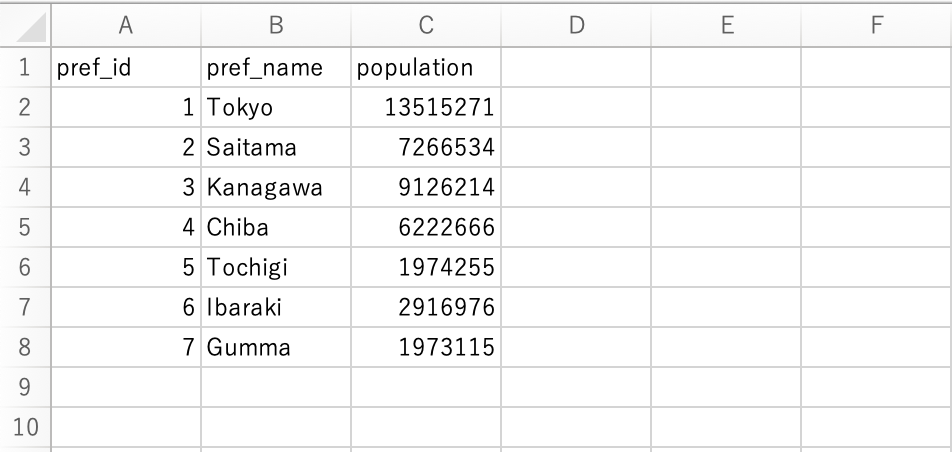
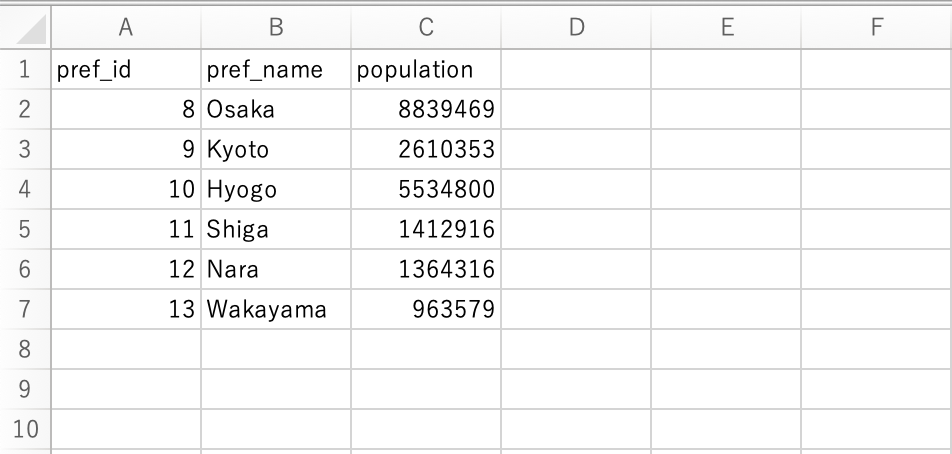
以下のような関東と関西の人口データのcsvがそれぞれあったとします。
それぞれ、
関東の人口データはpref_data_20220101というテーブルで、
関西の人口データはpref_data_20220102というテーブルで
作成してみます。
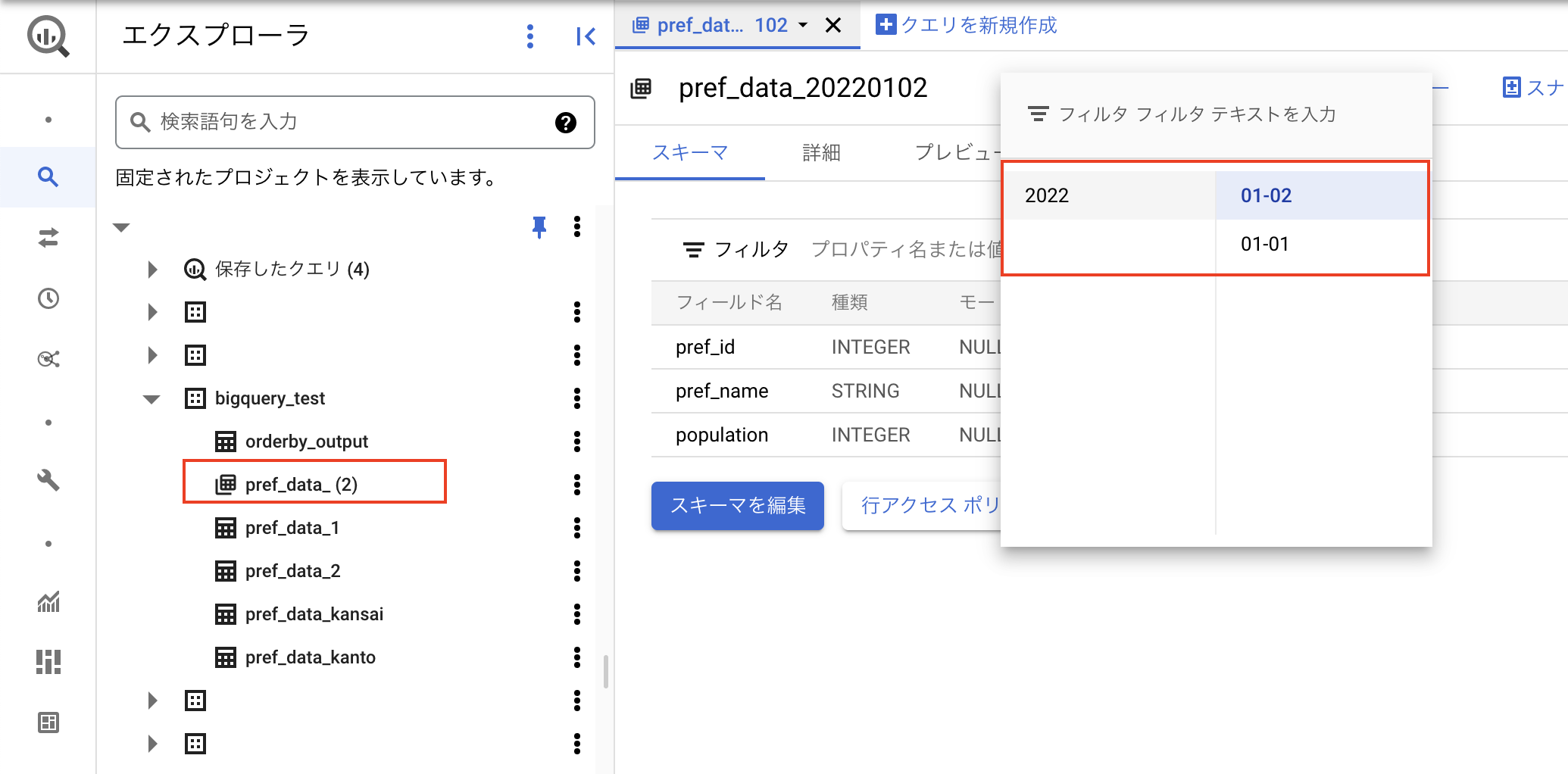
そうすると、以下の赤枠のように作成されます。pref_data_(2)で2つのテーブルが1つにまとめられている感じになります。
ちなみに、
同様にして同じ上記のデータで関東はpref_data_kanto、関西はpref_data_kansaiという名前でテーブル作成しても、まとめられず、
また関東はpref_data_1、関西はpref_data_2で作成しても、上記の画像のようにまとめられませんでした。
シャーディングの_TABLE_SUFFIX
シャーディングしたテーブルへは、_TABLE_SUFFIXというカラムを用いてアクセスすることができます。
BigQueryでは従量課金で、スキャン量が多くなるほどお金がかかります。
そしてBigQueryに限らずSQLは基本的にテーブルのデータ全量をスキャンします。
_TABLE_SUFFIXは正規表現になるため、*をつけることで全量のテーブルを参照します。
SELECT * FROM `< project名 >.bigquery_test.pref_data_20220102` ; SELECT * FROM `< project名 >.bigquery_test.pref_data_*` WHERE _TABLE_SUFFIX = "20220102"
上記2つともまとめられた(シャーディング)テーブルの中から必要なテーブルのみ参照するSQLです。
当然上のSQLはそのまま指定しているので、取得できます。
下のSQLでは、シャーディングされているテーブル名のYYYYYMMDD部分が*になっていて、その*の部分を_TABLE_SUFFIXで参照しています。
このようにして、シャーディングされているテーブルへアクセスできます。
もしシャーディングテーブル全てのデータを参照したい場合は、_TABLE_SUFFIXで条件せず、*のみでOKです。
別にそれなら、上のSQLでいいじゃんと思いそうですが、
複数の期間のデータを取りたい場合は、
_TABLE_SUFFIXはカラムなので、between andを用いて期間を指定することができます。
ここは_TABLE_SUFFIXでないといけない部分かと思います。そうしないとunion allで複数の日付で指定して取ることになってしまうため。
where _TABLE_SUFFIX between '20210701' and '20210706'
というように指定できます。
SELECT * FROM `< project名 >.bigquery_test.pref_data_20220102` ; SELECT * FROM `< project名 >.bigquery_test.pref_data_*` WHERE _TABLE_SUFFIX BETWEEN "20210701" AND "20210706"
*は正規表現でのアスタリスクを意味していて、ただそこに値が入るわけではないので注意。
上記でpref_data_20211231を作成して、2022年1月だけのテーブル全てを参照したい場合は、以下のようにすることで取得ができる。
SELECT * FROM `< project名 >.bigquery_test.pref_data_202201*`
そして以下のようにして、20220101テーブルを参照することもできる。
SELECT * FROM `< project名 >.bigquery_test.pref_data_202201*` WHERE _TABLE_SUFFIX = "01"
スケジュールクエリによるシャーディングテーブルの作成
スケジュールクエリでは、実行結果をどこにBigQueryテーブルのどこに吐き出すかを指定することができます。
そのため、毎日実行の場合、テーブル名に日付を指定しておけば、自動的にシャーディングテーブルを作成してくれます。
シャーディングの応用
シャーディングを複数参照する場合があるかと思います。
上でWHERE _TABLE_SUFFIXで*を指定していましたが、*がもし複数あった場合、この_TABLE_SUFFIXはどうなるのでしょうか?
*全てに同じものが適用されるのでしょうか。
このTABLE_SUFFIXはこの*に対して適用したいなどを指定することができます。
やり方としてはシャーディングのテーブルに対してAS(別名)を指定して、別名._TABLE_SUFFIXで指定することで、その別名にある*に対して_TABLE_SUFFIXを適用するという処理になります。
SELECT * FROM `< project名 >.bigquery_test.pref_data_*` AS pref_data WHERE pref_data._TABLE_SUFFIX = "20220301"