スケジュールクエリとは、GCPのソリューションであるBigQueryの機能で、
定期的にクエリを実行して、その結果をBigQueryのテーブルに吐き出すことのできる機能です。
GCP絡みの開発をする場合、重要な機能なので、簡単に紹介しようと思います。
自分の備忘録も含めて。
Contents
スケジュールクエリとは
スケジュールクエリとは、BigQueryでcronのようにある時間になったらクエリを自動的に実行したり、1時間ごとなど一定の間隔でクエリを実行したりすることのできる機能です。
定期的に実行させて、BigQuery内のテーブルに実行結果をエクスポートする機能になります。
データを毎日データ整形してそれを格納するテーブルを生成したりすることができるので、テーブルの最適化などを使い方によってできたりします。
あとはLooker Studioなどで直接大規模なデータにアクセスした上でカスタムクエリで処理するとLooker Studioで表示するときに表示速度が下がるなどよくないですが、Looker Studioで可視化するデータをスケジュールクエリで事前に最適化してそれを別テーブルに吐き出し、そこにLooker Studioでアクセスするなどすることで表示速度をそこまで下げずに表示させるなどの使い方もできるかと思います!
考え方次第で、如何様にも使えるのがこのスケジュールクエリです!
スケジュールクエリの作成方法
スケジュールクエリは、BigQueryのコンソール画面から、
以下のような赤枠からスケジュールクエリの設定画面にいくことができます。

実行したいクエリを記載して、以下の箇所から「スケジュールクエリを新規作成する」をクリックします。
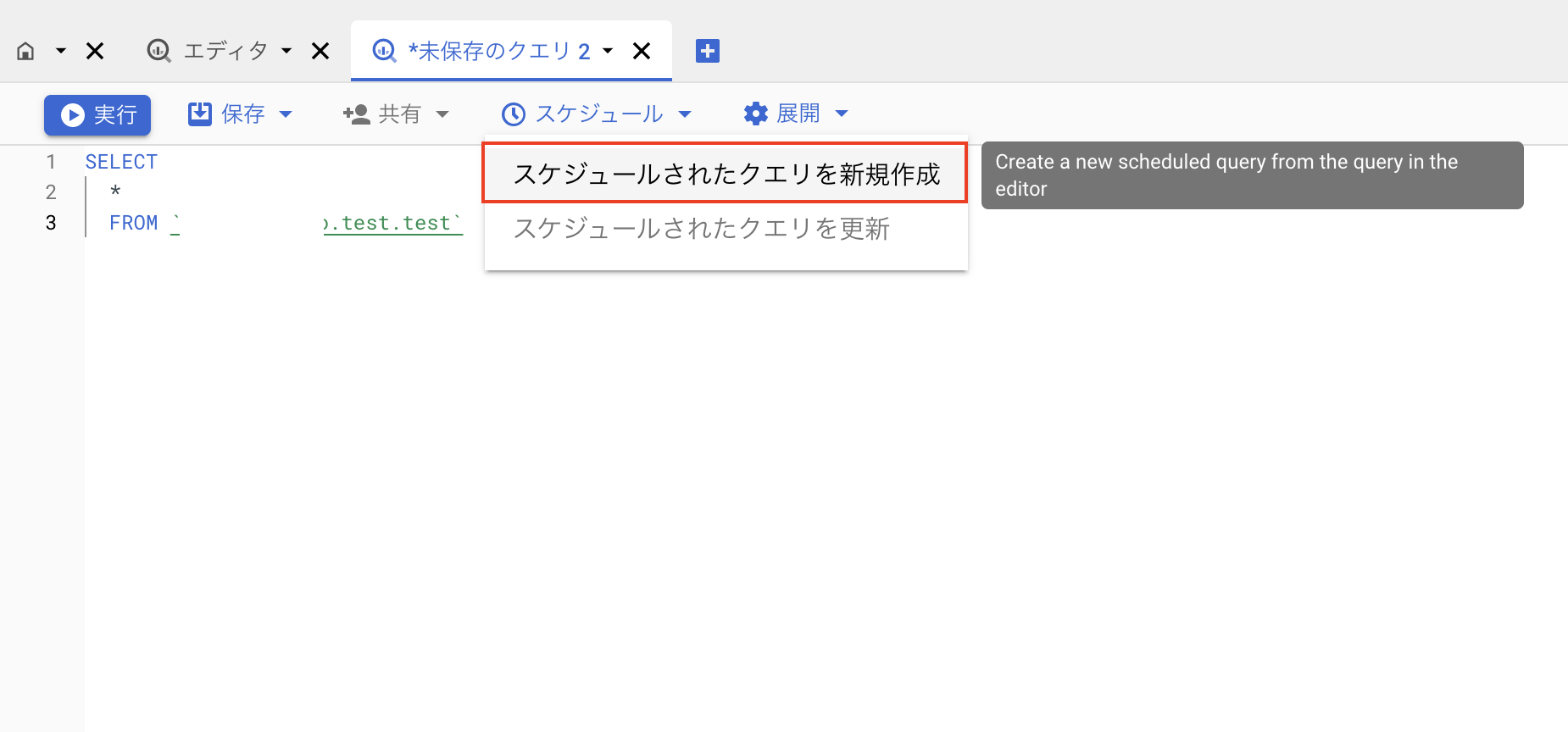
実行したい時間帯などを指定する
そうすると、以下のような画面が出て、いつ実行するか、どのテーブルに吐き出すかなどを設定していきます。
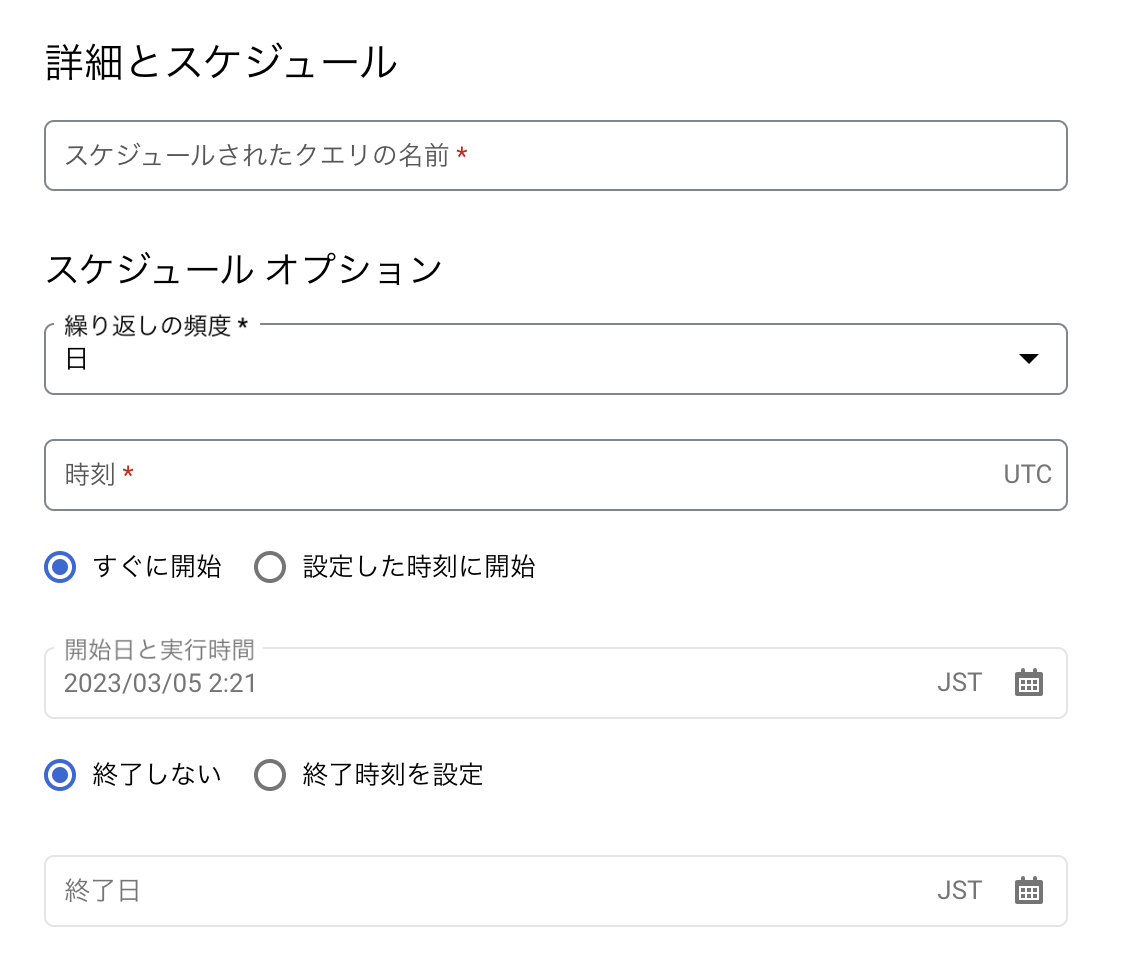
- \(①\) スケジュールされたクエリの名前:各自わかりやすい名前を指定
- \(②\) 繰り返しの頻度:日や時などを指定する。cronのように細かな時間設定をしたいのであれば、「カスタム」を指定する。以下カスタムを想定する。
- \(③\) カスタムスケジュール:cronのように指定することはできないので、以下のルールに則り記載する。
- \(④\) 設定した時刻に開始:いつからこのスケジュールクエリを定期実行するのかを指定する(特になければ、すぐに開始を設定)
- \(⑤\) 終了時刻を設定:いつまでこのスケジュールクエリを定期実行するかを指定する(特になければ、終了しないを設定)
every 1 hours from 00:30 to 12:30
Scheduleに関する指定について(Google Cloudヘルプページ)
※ cronのように、1 * * * *などと指定してもエラーで設定できません。
実行結果を吐き出したいテーブルを指定する
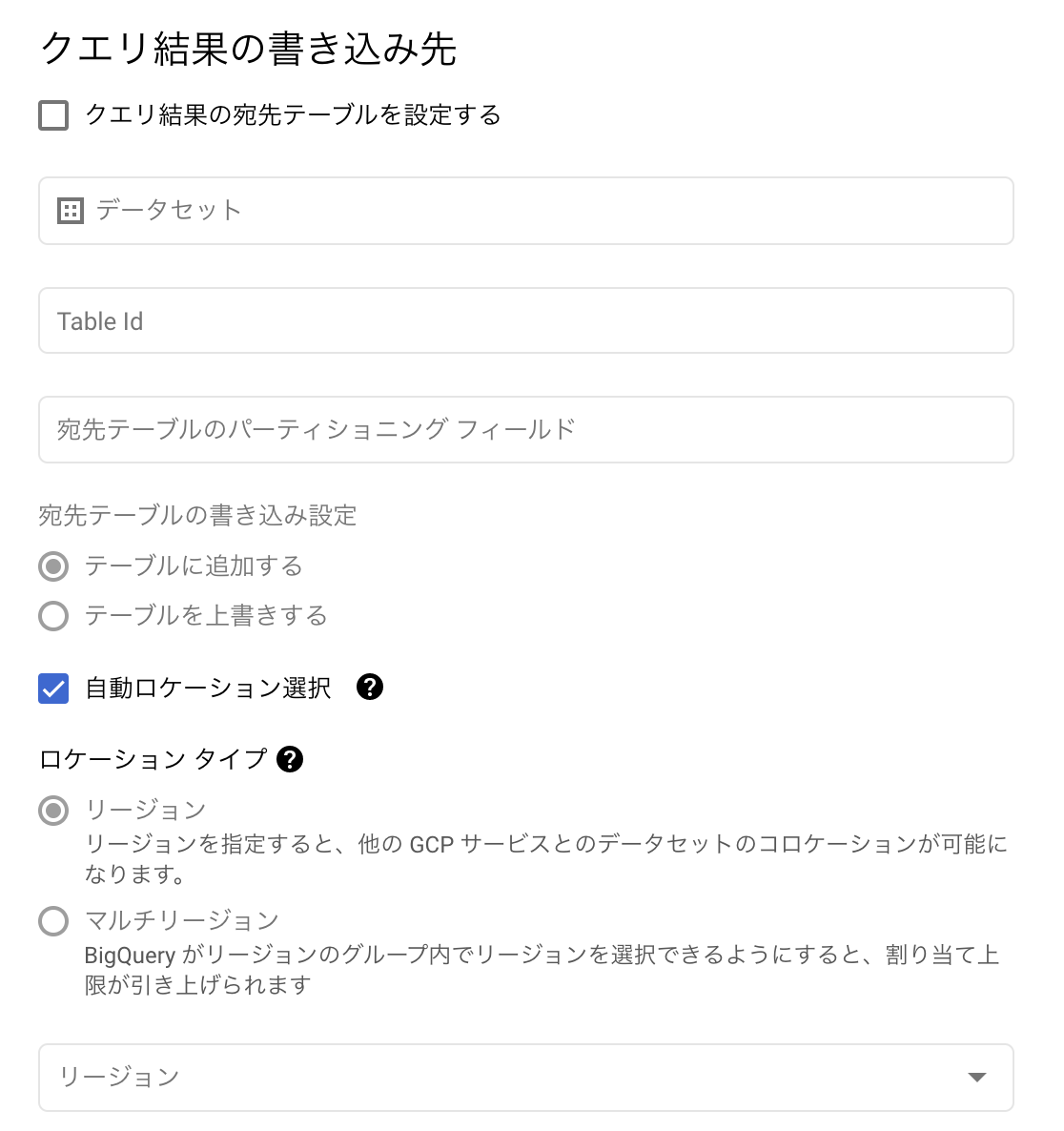
「クエリ結果の宛先テーブルを設定する」にチェックを入れて、BQのテーブルに吐き出すこと前提で説明。
- \(⑥\) データセット:吐き出したい先のデータセット名を指定する。
- \(⑦\) TableID:吐き出したいテーブル名を指定する。
- \(⑧\) 宛先テーブルのパーティショニングフィールド:パーティショニングしたいカラムを指定する。
- \(⑨\) 宛先テーブルの書き込み設定: 追加か上書き選択する。
- \(⑩\) 自動ロケーション選択:通常はチェックを外す。
- \(⑪\) ロケーションタイプ:リージョンで他のテーブルとの兼ね合いに応じてリージョンを指定する。
その場合、この後説明するスケジュールクエリで使用できるパラメータをTableIDのテーブル名に使用することで、シャーディングテーブルを作成することができます。
例) TableID:table名_{run_time-24h|”%Y%m%d”}
実行日が2023年3月2日の時、-24hなので、「table名_20230301」となります。
これで、保存することで、スケジュールクエリの作成が完了し、これによって指定した時間に定期実行してくれます。
スケジュールクエリの実行期間/間隔の指定
上でカスタムスケジュールで、ある時間で定期実行するような設定をしました。
ここではもう少し詳細に確認してみます。
スケジュールクエリの実行期間は以下のものを指定することができます。
以下では例として、定期実行とある時間帯での定期実行の設定方法を記載しています。
| 項目 | 例 |
|---|---|
| 定期実行 | 毎日9:00に実行したい場合は、「繰り返しの頻度:毎日」「開始日と実行時間で実行時間を9:00にする。開始日はなんでもOK」 |
| 時間帯 | 例えば、every 1 hours from 00:45 to 14:45 (UTCで00:45-14:45設定) |
スケジュールクエリでのみ使用できるパラメータ
上で宛先テーブルのTableIDで、シャーディングテーブルの作成について説明しました。
例えば毎日1回実行するとかであれば、出力先テーブルで日付でパーティションを切るなどのことをしたいと考えるのが普通かと思います。
スケジュールクエリでは1つのテーブルに吐き出すのではなく、日付パーティションを切ってそれごとに吐き出すみたいなことをすることができます。
BigQueryでは、テーブル作成するときに、
テーブル名_20201231
というように指定すると、自動的にシャーディングを切ることができるように、
スケジュールクエリでも宛先テーブル名に上記のような指定をすることで、同様のことができます。
上記を実現するためには、スケジュールクエリでしか使用できないパラメータ
- @run_time
- @run_date
を使います。
主にこれらのパラメータは2つの方法で使用ができます。宛先テーブル指定とクエリです。
https://cloud.google.com/bigquery/docs/scheduling-queries?hl=ja
宛先テーブルに使用
table名_{run_date}
table名_{run_time-24h|”%Y%m%d”}
というようにtun_dateやtun_timeといったパラメータを指定することで、
テーブル名に日付シャーディングを作成することができます。
宛先テーブルに使用
実行するクエリ内にパラメータを使うことができます。
出力先テーブルについて
スケジュールクエリを設定すると、
もしその出力先のテーブルが存在していない場合は、自動的にテーブルを生成してくれます。
そこで疑問に思うのは、じゃあそのテーブルのスキーマ名やデータ型はどうなるのか?
それは、
出力する際のクエリの別名(AS)で出力されます。
スケジュールクエリで、
select CURRENT_TIMESTAMP() as created_atとした場合、出力先のテーブルがない場合は、
スキーマはcreated_atで出力の値はTIMESTAMPなので、TIMESTAMP型で生成されるようになります。
created_atでCURRENT_TIMESTAMP()で作成
前日15:00:00-今日14:59:99までが昨日のデータとしてパーティションを切る
where created_atでDATE型で指定してもその日付のパーティションでデータ取得できる。
スケジュールクエリではクエリ実行完了後、通知先としてpubsubのtopicに通知することができます。
これによりpubsubのtopicをトリガーにできる、Cloud Functionsなどで、
クエリ完了後に何らかの処理をpythonやnodejsでしたいなどがあれば、実行させることができたりします。
CURRENT_TIMESTAMP()ではUTC時間で実行される。
これでパーティションを切った場合、14:59:99999999-15:00:0000000