BigQueryを使ったシステム開発を行うとなった場合、気になるのはBigQueryのスペック。
グローバルリソースなので、みんなでリソースを共有するため、使う時間によってはスロットがなく処理が遅いことなどもあります。
最大で使用できるスロットは2000スロットです。
簡単に説明するとBigQueryの処理を行うのがスロットというCPUみたいなもので、それをみんなで共有して使うので、処理が遅くなったりもします。
その中で自分が実行したクエリがどのくらいスロットが使われているのかなどを確認したい場合があると思います。
そういう時に使うのがインフォメーションスキーマです。
これを使うことで、以下のような情報を取得することができます。
BigQueryで実行したクエリのスロット数などを確認する
過去に実行したクエリで使用したスロット数や、処理時間などの情報を得ることができます。
他にも取得できるデータ
SELECT
job_id
,job_type
,start_time
,end_time
,TIMESTAMP_DIFF(end_time,start_time,MILLISECOND) AS elapsed_time
,total_slot_ms
,total_slot_ms / TIMESTAMP_DIFF(end_time,start_time,MILLISECOND) AS avg_slots
,query
FROM
`region-asia-northeast1`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
ORDER BY
start_time DESC
`region-{region_name}`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
インフォメーションスキーマの情報は、クエリ実行などをした環境のリージョンを指定します。
上のSQLのfrom句には、`region-asia-northeast1`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
とありますが、東京リージョンで実行したクエリに対して情報を取得するという意味です。
`region-{リージョン名}`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
の{リージョン名}の箇所に、リージョンを指定します。
そして東京リージョンasia-northeast1を指定した上記のクエリ実行結果は
以下のようになります。
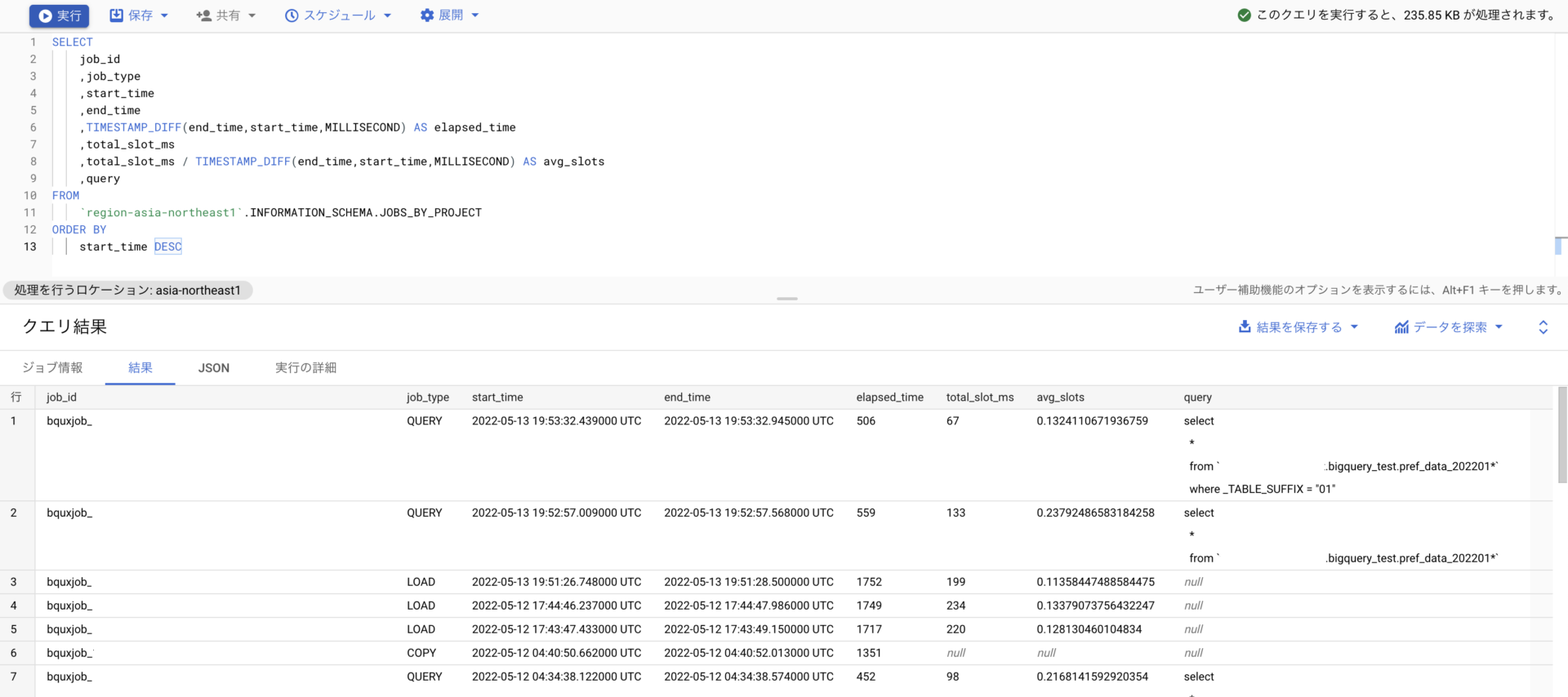
job_typeは、
queryはその名の通りクエリ実行のjob、
loadはGUIでのファイルなどをアップロードしたり、Cloud Storageなどから読み込んでテーブル作成するjob、
copyはクエリ実行した結果を別テーブルに吐き出すjob
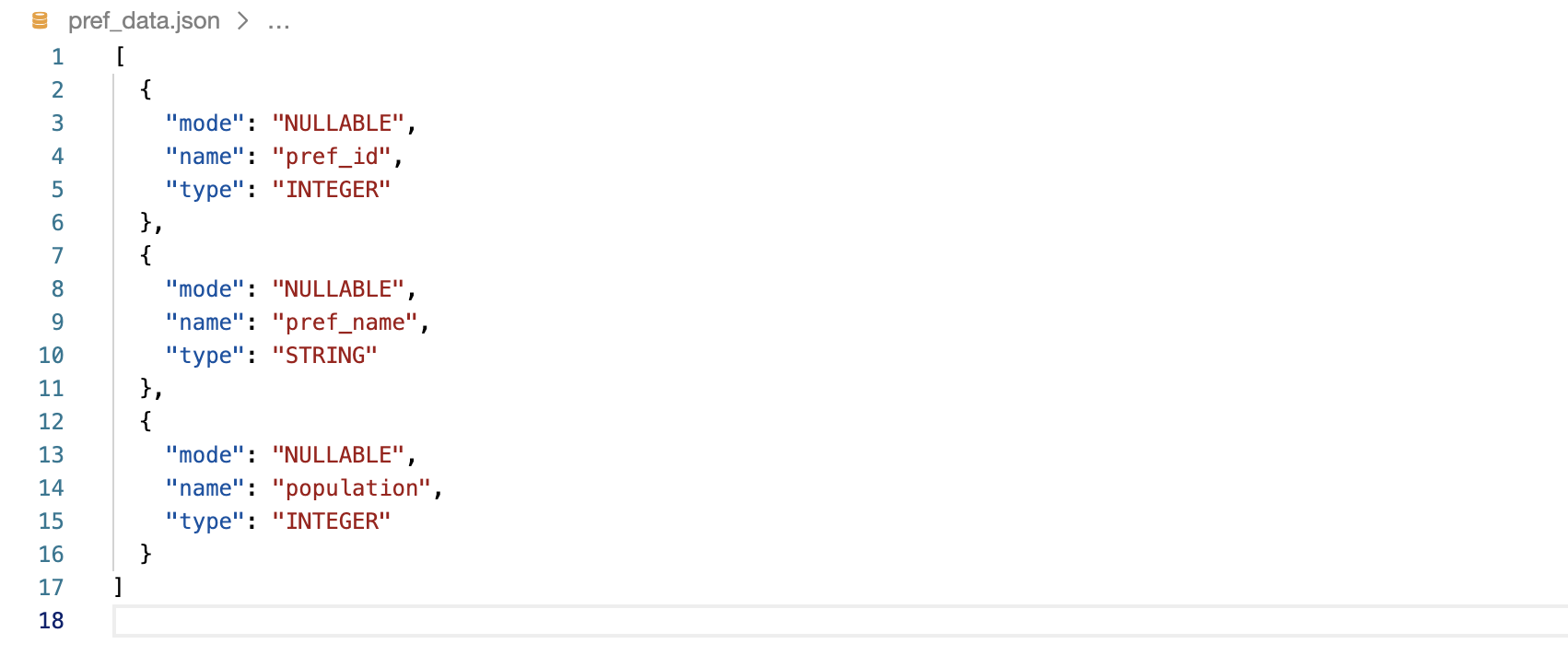
BigQueryのテーブルのjsonスキーマ取得
Cloud Shellやローカルでgcloud SDKが入っている環境であれば、
bqコマンドを叩いて対象テーブルのjsonスキーマを取得することができます。
bq show --schema --format=prettyjson bigquery_test.pref_data_20220101 > pref_data.json
実行すると以下のようにjsonスキーマが出力されます。