
- BigQuery Data Transfer Service
- BigQuery Omni
- BigQuery ML
- マテリアライズドビュー
Contents
BigQuery Data Transfer Service
自動的にある時間で、BigQueryへのデータ取り込みをしてくれる。
これにより、さまざまな箇所からBQへのデータ転送をしてくれるので楽になる。
ある時間ということなので、基本的にバッチ処理かな?streaming料金は発生しないかなと。
https://cloud.google.com/bigquery-transfer/pricing?hl=ja
以下でBigQuery Data Transferを利用できます。ここをクリックします。
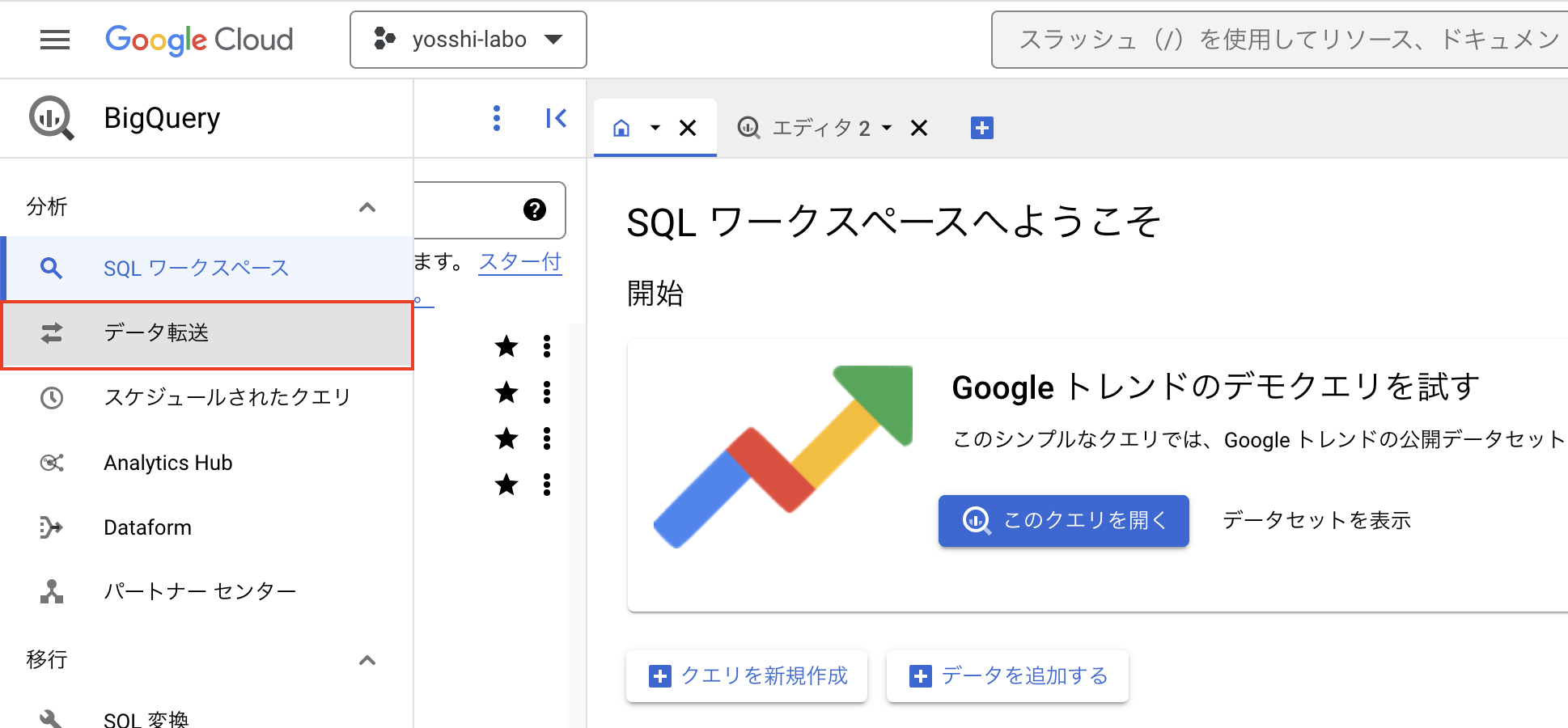
今あるBQのデータを別プロジェクトにコピーする(そのまま移転したい)場合は、Dataset Copyを選択。
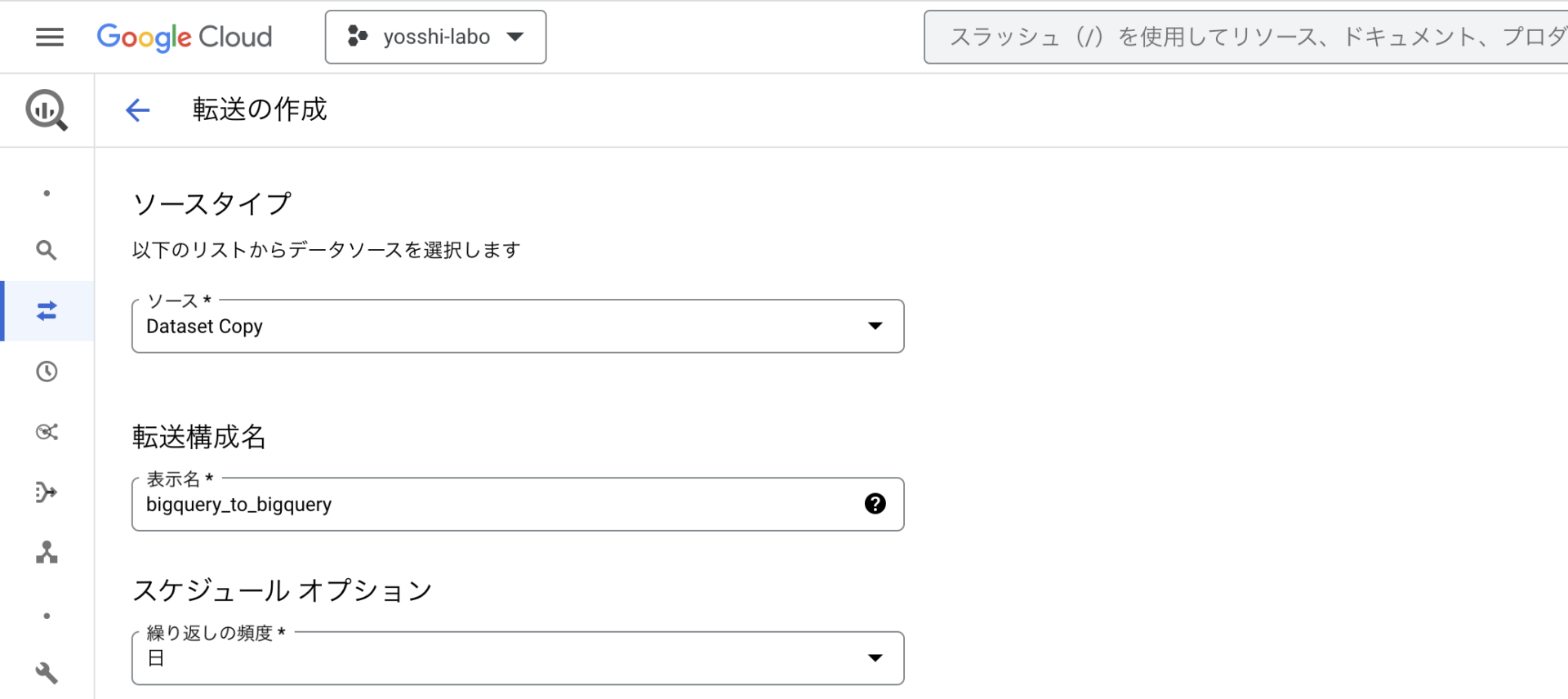
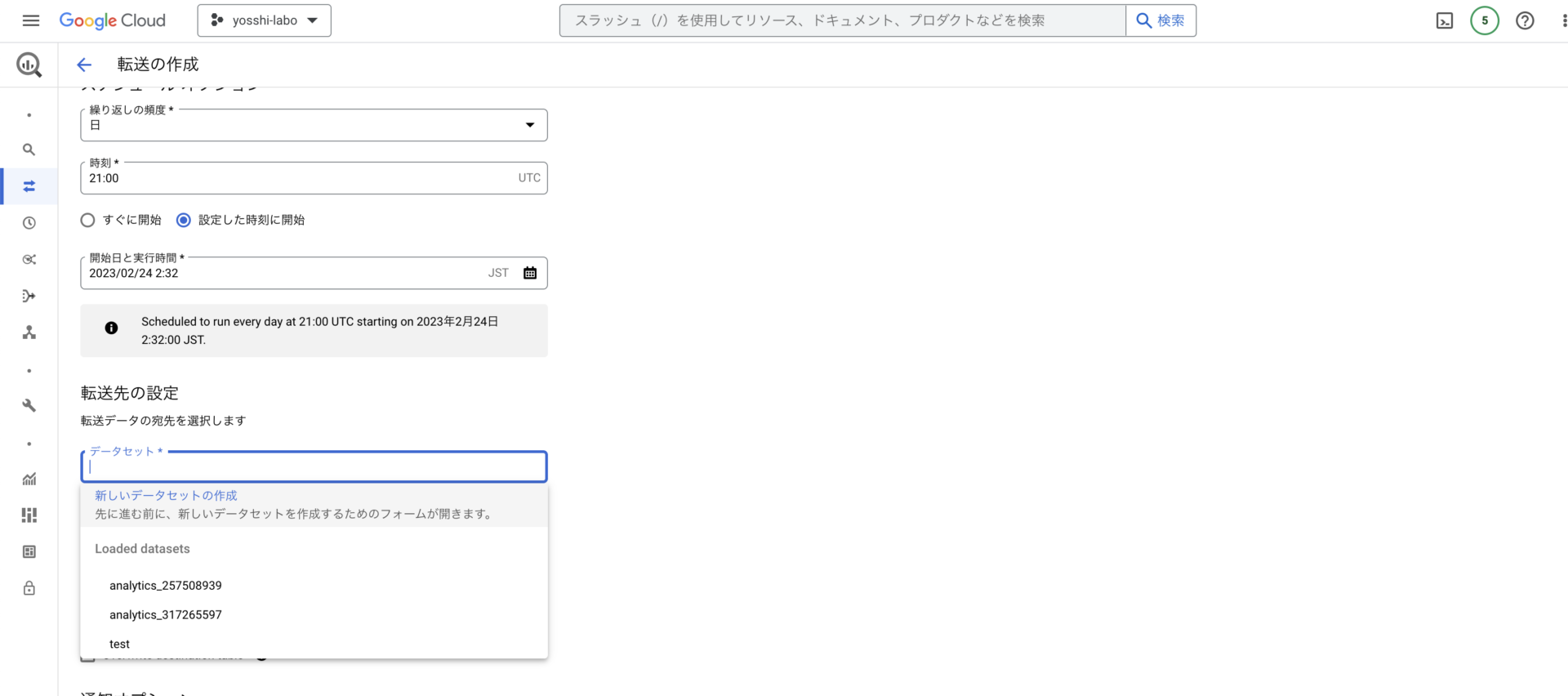
以下のところで、別プロジェクトへ転送する設定が可能です!
「新しいデータセットを作成」を選択
使いどころ
よくある場合としては以下2つかなと思います。
\(①\) AWSなどに貯めていたデータを今後はGCPに移行したいとき
→ RedshiftやS3などのAWSに貯めているデータをgcpに移行したいなーみたいなことがあると思います。例えばGA4使っていて、ローデータを吐き出せるのがBQなのでGCP上でさまざまなことをしたいなーというとき。
\(②\) GCP内のあるプロジェクトにあるデータを、別のプロジェクトにデータ移転させたいとき
→ 昔使っていたGCPのAプロジェクトだけど、他の部署が別にBプロジェクト立てていて、会社としてもそのBプロジェクトを本番で今後どんどん使っていこう!となったときに、AプロジェクトからBプロジェクトにデータ移転をしたい場合。
結構いろんな場面でこのBigQuery Data Transferを使う場面はあるかと思います!
スケジューリングできるので、毎日ある時間になったら転送するみたいなことができるので、かなり有用性は高いサービスですね!
BigQuery Omni
BQのリソースを使って、AWSやAzureのデータに対してクエリする機能だが、これはAWSのデータを何か移動したりするわけではないので、AWSとかで料金は発生せず、あくまでBQのクエリ実行料金のみ。
通常のオンデマンドでの料金。
https://cloud.google.com/bigquery/docs/omni-introduction?hl=ja#:~:text=%E3%82%AF%E3%82%A8%E3%83%AA%E3%81%AF%20Google%20%E3%81%AB%E3%82%88%E3%82%8A%E7%AE%A1%E7%90%86,%E3%81%AF%E8%AB%8B%E6%B1%82%E3%81%95%E3%82%8C%E3%81%BE%E3%81%9B%E3%82%93%E3%80%82
BigQuery ML
BigQueryでSQLを書いて、機械学習や統計的な手法で分析をすることのできる機能。
SQLチックにCreate Modelでモデルの作成をして、それで分析できる。
現在できる分析手法としては、
ロジスティック回帰、線形回帰分析、クラスター分析が主。
モデルを作成すると、テーブルと同じ個所にモデルが作成される。
もし他の分析手法をしたい場合は、Auto ML Table等を使ってモデル構築となる。
https://yosshiblog.jp/gcp_bigquery-bqml/
マテリアライズドビュー
マテリアライズドビューとは、別に作成して自動的に更新してくれるテーブルを作成する機能になります。
ん?よくわからん!ってなると思いますね、、
よくビューと比較されることがあります。
MySQLではビューという機能があります。
ビューでは、実体としてテーブルがあるわけではなく、参照型のテーブルになります。
マテアライズドビューの作成方法はクエリによる作成しかない。
そして、簡単にCREATE TABLEのような書き方で、CREATE MATERIALIZED VIEWを最初に作成して、ASつけて、作成をする。簡単にマテアライズドビューの作成が可能になる。
CREATE MATERIALIZED VIEW yoshida-labo.analytics_257508939.mat AS SELECT distinct event_name FROM `analytics_257508939.events_20230201`
これを作成すると、MySQLのViewのように自動的に処理が走り、データの更新がなされます。
ただ、クエリの中にアスタリスクを入れることができないみたいで、アクセスログには相性良くないかもですね。
あるテーブルを作成して、それによってdistinctでマテリアライズドビューを作成します。
そして作成したテーブルの中に1行追加して、distinctしてすでにある値ではなく、別の値を入れてみます。
そうすると、自動的にマテリアライズドビューにかかっているSQLが自動的にトリガーとなってSQLを実行して処理の書き換えを行ってくれます。
実際、マテリアライズドビューの中で、
insert `yoshida-firebase-test.test.testest` values ("user_engagement", 80)
よくあるMySQLでの事例としては、合格者の情報のみを引っこ抜きたい場合、合格者もリアルタイムでいつでも受けて合格できるわけなので、
週1回SQL叩いて抜き取ることもできます。
でもリアルタイムで更新かけたい場合があるとします。
後続で例えば試験に合格すると、このページにアクセスできさまざまなサービスを利用できるようにしたいとかの場合ですね。
Viewには合格者情報が入ってるので、今合格した人の情報もそこに入り、合格者の最適情報があります。確かに過去の試験結果の情報からこの人合格してる判定などしても良いですが、
データ量が膨大になり、処理に時間がかかります。
なので、こうならないように、ビューに貯めておくほうが良いですね!
マテリアライズドビューの作成
今回は検証のため、簡単に以下のようなcsvファイルを取り込んでテーブル作成し、そのテーブルからマテリアライズドビューを作成して、自動更新されるかどうかを確認してみます!
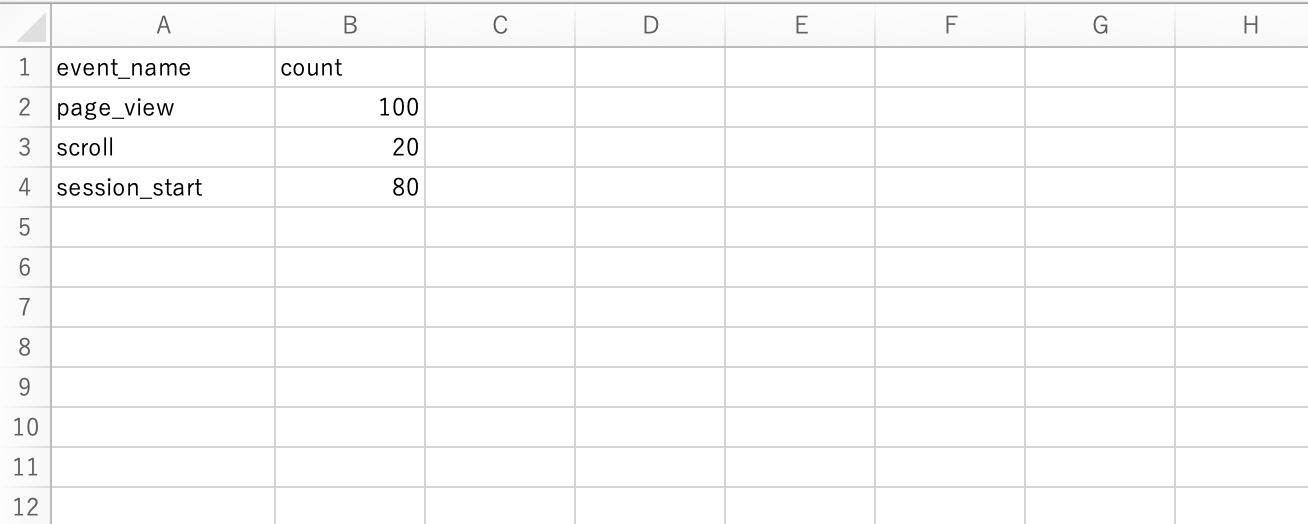
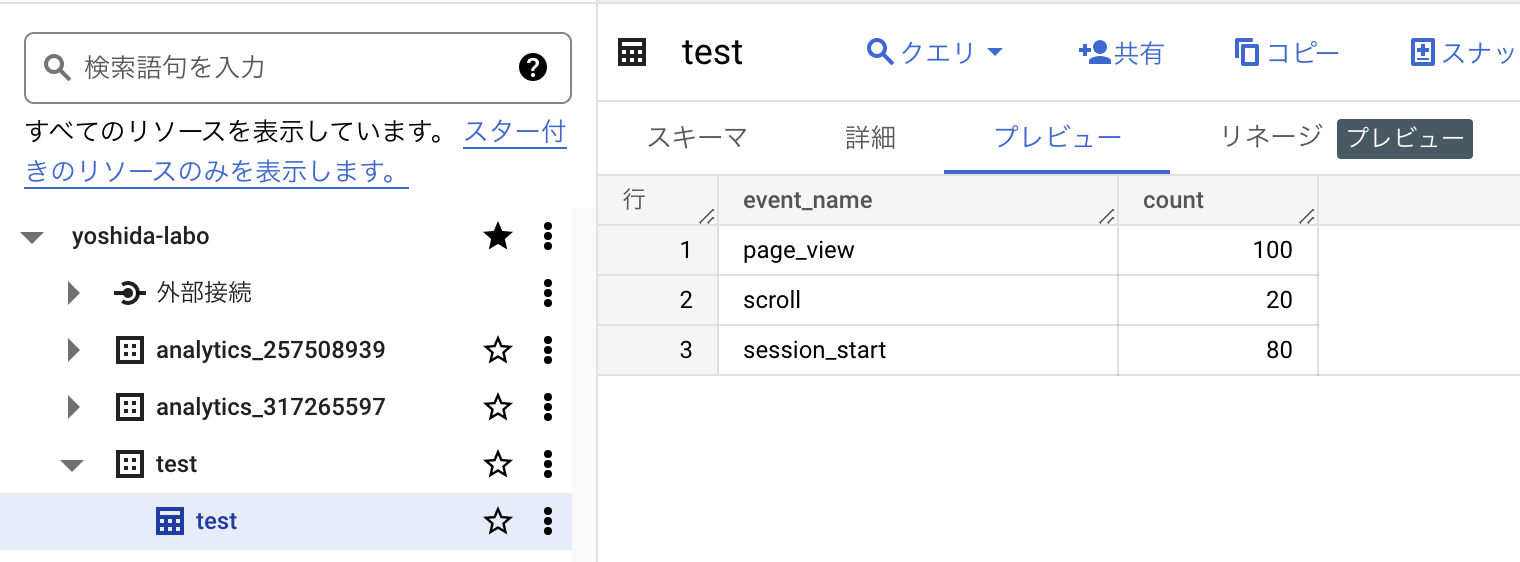
取り込むと、以下のようにテーブルを作成されました。
そして、このテーブルをベーステーブルにして以下のマテリアライズドビューを作成するクエリを実行します。
CREATE MATERIALIZED VIEW yoshida-labo.test.materialized_view AS SELECT distinct event_name FROM `yoshida-labo.test.test`
そうすると、以下のように「materialized_view」という名前のマテリアライズドビューが作成されました。
event_nameをdistinctしたので、確かにこのViewには3レコードで、event_nameのみが入っていると詳細画面に記載されてますね!

詳細の一番下を見ると、生成されたビューは作成されたクエリが表示されています。そしてこのクエリが今後定期的に実行され、このビューに更新かけたり追加したり削除したりしてくれるようになります。というよりは上書き処理になるかなと思います。そして上の画像には更新間隔(ミリ秒)は1800000(5分)となってますね。なので、このビューは5分ごとにこのクエリを実行して、このビューを更新します。

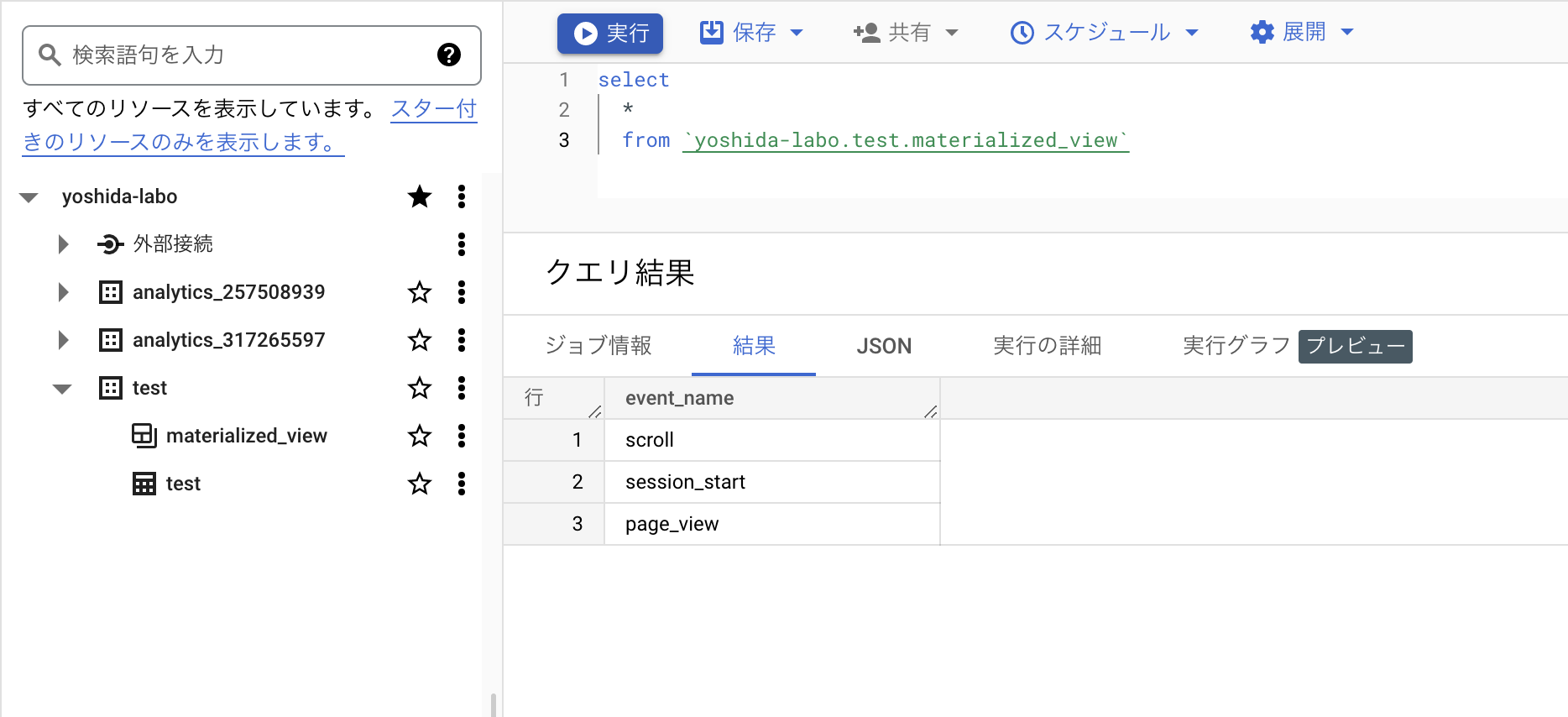
そして作成したmaterialized_viewのデータを見てみたいと思います。現時点でevent_nameをdistinctした結果なので3レコード入っていると想定できます。
普通のselect文を実行してみると確かに想定通りのデータですね!
SELECT * FROM `yoshida-labo.test.materialized_view`
では、ここでこのmaterialized_viewが参照しているtestテーブルに一行レコードを追加してみます。以下を実行します。
insert `yoshida-labo.test.test` values ("user_engagement", 80)
そうすると、materialized_viewは参照しているtestテーブルにデータが追加され、更新時間である5分後に再度クエリが実行されて、このuser_engagementが追加され、4レコードになると想定できますね!
更新時間の変更
デフォルトでは更新時間は5分になります。
ただもっとリアルタイムに更新かけたい!などもあると思います。そういう場合は、マテリアライズドビューを生成するクエリの中でOPTIONS指定することで可能になります。
更新の最小値は60秒です。
以下の2行目で60秒(1分)更新を指定してます。
CREATE MATERIALIZED VIEW yoshida-labo.test.materialized_view OPTIONS (enable_refresh = true, refresh_interval_minutes = 60) AS SELECT distinct event_name FROM `yoshida-labo.test.test`
マテリアライズドビューの制約や料金
https://cloud.google.com/bigquery/docs/materialized-views-intro?hl=ja#limitations
使いどころ
毎回処理をするようなクエリの場合や、条件に合ったユーザーリストやセグメントリストを自動的に生成してくれるという点はなかなかメリットではないかなと思います!
ComposerとかでpythonやDAGの中でクエリを実行してそこで、一から条件を満たすユーザーを取得する処理をするとどうしても処理に時間がかかったり、いろんなクエリが走ってエラーになる可能性もあったり、エラーになった場合どこでエラーになったのか特定も複雑になります。
なので、あくまでこのマテリアライズドビューで条件に合ったユーザーリストを作ってしまい、Composerからどこかにセグメントリストを転送する場合、そのマテリアライズドビューをただSELECT * FROMするだけで、簡単に取得できるようにしたほうが、役割分担もよく、管理もしやすいかと直感的に思いましたね!
皆さんの意見など聞いてみたいですね!