
NumpyとPandasとは?
Pythonのライブラリで様々なデータを配列だったり、データフレーム、行列に変換することのできるライブラリのことです。
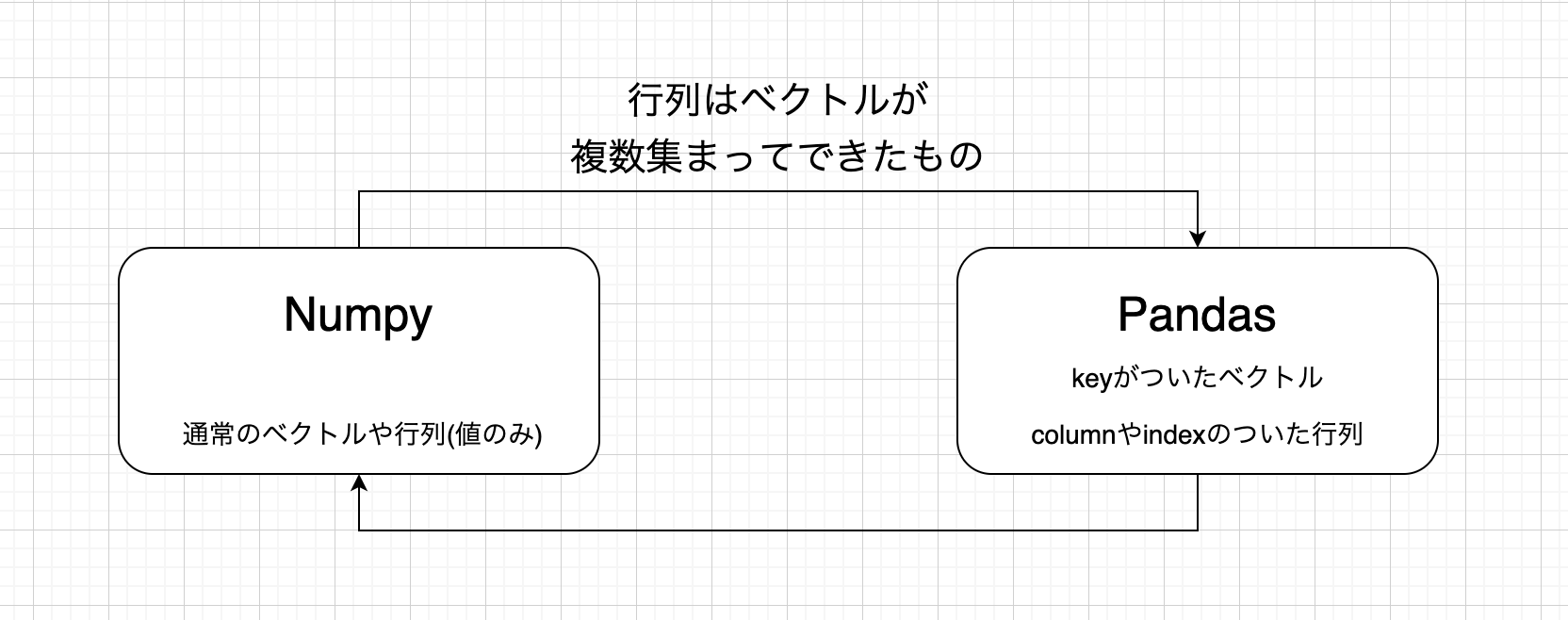
NumpyとPandasの関係性
Numpyは数値の配列を簡単に作成できます。主に数列など!
さらに数列が作れるのであれば行列もNumpyで作成できます。
そしてPandasでも数値の配列や行列の作成ができます。
え?じゃあNumpyとPandasの違いってなんだろう!
それはキー(index)を持つかどうかです!
Numpyでは配列の各要素に対してkeyがなく、アクセスする場合はa[0]やa[4]のようにアクセスします。
そして行列も作成できますが、行列は配列の集合体(厳密にはベクトルの集合体)で、
こちらもa[1,1]などのようにアクセスします。
逆にPandasではindexをつけることができるので、
a["orange"]だったりでアクセスできますし、
numpyでいう行列は、pandasではデータフレームといい、これはa["column","row"]のようにindexでアクセスすることができます。
ちなみにnumpyでいう配列はSeriesと言います。
phpで言えば連想配列的なイメージです。
上記のことから、
numpyで生成した配列や行列を使って、pandasではSeriesやDataframeを作成することができます。
https://numpy.org/doc/stable/reference/distutils_guide.html
コード
import numpy as np
np.arrange(5)
np.arrange(6).reshape((2,3)) # 2,3次元配列(行列)
np.zero(3) # 3次正方行列(すべての要素を0にする)
np.ones(3) # 3次正方行列(すべての要素を1にする)
# ランダム系
np.random.uniform() # 平均、分散を指定するとそのランダムを算出してくれる
np.random.rand() # 一様分布
np.random.normal(a, b, size) # 平均a, 分散b、個数sizeの正規分布
np.random.randn() # 標準正規分布(平均0, 分散1)
np.random.beta(a,b) # ベータ分布
import numpy as np
import pandas as pd
# numpyからpandasの形式に変換する
# numpyの1字形式からseries
# numpyの2字形式からdataframe
# numpyからpandas形式に変換
pd.Series(np.arrange(5), index=) # Series
pd.DataFrame(np.arrange(6).reshape((2,3)), index=, columns=) # DataFrame (index=行, columns=列)
# カラム名取得
dataframe.index
dataframe.columns
# インデックス名の変更
Series.reindex([,,,]) # Seriesの行の名前を変更する
DataFrame.reindex([,,,]) # DataFrameの列の名前を変更する
DataFrame.reindex([,,,], axis=1) # DataFrameの行の名前を変更する
DataFrame.reset() # index, columnsのindex名、などを削除して0,1,2,3..という初期の値を入れる
# 列単位、行単位の取得
Series.ix[]
DataFrame.columns名 # dataframeでの列の取得
DataFrame.ix[index名] # dataframeでの行の取得
# DataFrameのピンポイントの取得 → 新たなdataframeを作成
# データの取り込み
# csvやtsvデータなどは基本的に複数行となる。(戻りはDataFrame)
pd.read_csv('') # csv専用の読み込み。csvなのでシートは1つのシートのみなので、引数にシート名はない
pd.read_table('', sheet_name="", sep="") # excel、txt、tsvなどいろいろ読み込める。excelの場合はどのシートを読み込むかを指定。txtで,区切りなら、sep=","を指定
pd.read_clipboard() # クリップボードのデータをDataFrame化する(ctrl+CでコピーしたものをDataFrame化する)
# 要約統計量
dataframe.sum() # 列ごとに合計値を出力
dataframe.sum( axis = 1 ) # 行ごとに合計値を出力
dataframe.min() # 列ごとに最小値を出力
dataframe.min( axis = 1) # 行ごとに最小値を出力
dataframe.max() # 列ごとに最大値を出力
dataframe.max( axis = 1) # 行ごとに最大値を出力
dataframe.cumsum() # 累積合計値を埋め込んでいく(1行目から累積で表示。そのため順番が大事。)
dataframe.describe() # dataframeの詳細情報を出力(主に要約統計量)
# 列の削除
del DataFrame.columns名
DataFrame.drop([columns名]) # 指定したカラムを削除(複数の場合はlistで指定)
DataFrame.drop([index名], axis=1) # 指定したindexを削除(複数の場合はlistで指定)
# NAを探す
DataFrame.naAll()?
# 列ごとに処理を適用する
dataframe.apply( lambda { 行ごとに実行したいロジック } ) # 列ごとに処理を行う
# データフレームの上位5件(デフォルト)を表示
dataframe.head()
dataframe.head(10) # 10件表示
# データフレームの下位5件を表示
dataframe.tail()
# データフレームの表示
display(df)
# 既存データフレームにカラムの追加
# dfに顧客番号、商品カテゴリ、商品カテゴリ単価、購入数、受注日があったとして、これに新たなカラムとして「購入額」を追加したい場合
df["購入額"] = df["商品カテゴリ単価"]*df["購入数"]
# 普通に追加すればいい
# ============ SQLチックなこと。(SQLでできることを) ============
# ① join
# 複数のdataframeのmerge(2つが同じキーの名前)
pd.merge(df1, df2, on='顧客番号')
# ② group by
# pandasでもgroupbyです
.groupby('顧客番号')
# ③ order by
# pandasではsort_values()で行います。
sort_values('受注日', ascending=True)
# ④ where
# pandasでは色々やり方はあります。
df[df['受注日'] > '20220101']] # データフレームの受注日が2022年のもののみに絞る
df[df['受注日'] > '20220101' && df['商品カテゴリ'] == "商品AA"]] # 2022年で、商品AAのみ
# ⑤ having
# 普通にgroupbyしてsumか何かした後のデータフレームに対して④を行う
# ⑥ limit
# 並び替えをして
.head(10) 上位10件
.tail(8) 下位8件
SQLチックなことのところは、
これらはカラムを指定してorderbyしたり、groupbyしたりしています。
カラムを指定する、、カラムがないと使用できないので、numpyではカラムはなくただのベクトル、行列なので、データフレームというpandasを利用しないとこれらの処理はできません。
numpyはあくまで数値を生み出したり、数値に対して何かをするというものです。
なのでサンプルデータを生み出したり、規則性のあるような数値をサンプリングしたりするのに使い、
そこで生まれたベクトルや行列を、pandasで使えるように
pd.Dataframe(numpy型)
でpandasで、そしてデータフレームで扱えるようにします。
groupby
Rもそうですが、関数型言語であるため、メソッドチェーンができます。
groupbyにはグルーピングしたいものを指定します。
以下では顧客番号でグルーピングする例が出てますが、顧客番号だけでなく、顧客番号×商品カテゴリで顧客番号粒度だと、顧客番号ごとに売上を出したりしますが、
顧客番号と商品カテゴリをかけることで、この組み合わせごとに売上を出してくれるので、ユーザーごとにどんな商品を好んで買うのかを集計できます。
df[['顧客番号','受注日']].sort_values('受注日', ascending=True).groupby('顧客番号').tail(1).rename(columns={'受注日':'最新購入日(受注日)'})
そして複数指定したい場合は、以下のようにリスト化することで、使用できます。
df[['顧客番号','商品カテゴリ','受注日']].sort_values('受注日', ascending=True).groupby(['顧客番号','商品カテゴリ']).tail(1).rename(columns={'受注日':'最新購入日(受注日)'})
pythonでは複数の値を扱いたい場合は、リスト化して指定するのが通常です。
グルーピングしたいデータをdfから選択します。
それがdf[['顧客番号','受注日']]
そしてその後、sort_valuesで受注日に対して昇順に並び替えています。
そのデータフレーに対して、groupby('顧客番号')ということで、顧客番号ごとに処理を行い、
その処理にtail(1)つまり、昇順に並び替えている状態での各顧客番号ごとのtail(1)なので、最新受注日を取得します。
その結果、
出力されるデータフレームは、各顧客番号の最新受注日のデータフレームが作成されます。
groupbyで出力されるデータフレームに対して、カラムを最後変更して、現在のカラム名「受注日」→最新購入日(受注日)に変更して終了します。
適用する関数の順番によって処理の結果は変わります。
pandasやnumpyは直感的でわかりやすく、
基本的にデータフレームに対して関数を適用して、その関数の戻り値がデータフレーム型であれば、また別のデータフレーム対応の関数を適用して、、、の繰り返しなので、
今データがこういう処理されてこういう形になるから、次はこの関数でこうして、、、っていう想像がつきやすく、データ整形にはもってこいなライブラリですね。
javascriptのjqueryのようなメソッドチェーンですね。関数型言語の特徴であったりします。
※ groupbyをした結果は、
という形になります。
そのため、groupbyをした結果はindexが外れてしまいます。indexは1行目、2行目など、データフレームを表示した際に一番左に表示されるレコードのことですが、それらが消えてしまい、データフレームの中に組み込まれてしまいます。
そうなるとデータフレームの中に余分なデータが入ってしまいめんどくさくなります。なのでそうならないように、
groupbyの後に、reset_index()とすることで、元のindexを貼ってくれます。
groupbyには集計したい軸、つまりディメンションを指定します。ディメンションの指定は何個もできます。
そしてgroupbyを実行するdfの中ではそのディメンションとgroupbyによって集計したい処理したいメジャメント(数値)を置きます。
これにより集計されますが、
groupbyを実行するdf[['顧客番号','受注日']]の中に商品カテゴリがないのに、groupbyで指定することはできません。
型変換
通常、csvなどを読み込む場合は、データフレームで読み込みます。csvにはカラムがあるので。
でプログラムはAIではないので、ひとまず全てのカラムの型は、object型という型になります。
売上情報のcsvとかだと、個数は数値ですが、データフレームで読み込むとデフォルトでobject型になります。
なのでその型をint型に変換したい場合は、
df = df.astype({'金額': int, '数量': int})
のように指定します。
df = df.astype({'型を変更したいカラム名': 'どの型にしたいか'})
なので、上の例だと、金額というデータフレームのカラムの型をint型に変換し、数量というカラムをint型に変更するという処理です。
変更しないといけない理由としては、
object型で数値を扱ってしまうと、
例えばsumなどの集計関数では、集計なのでint型などの数値系の型をもつカラムでしか演算ができなかったり、
さらにはデータフレームの条件を絞りたい時、マイナスではなく数値がプラスのものに絞りたい場合に、object型だと
==
などで比較ができません。
int型にすることで、数値の比較ができるようになり、条件で絞れるようになります。
Numpyによるデータ生成
array creation routinesとある通り、規則性のある値の配列を作成します。
numpy.arrangeであれば等差数列の配列
numpy.zeroであれば0しか入らない配列
https://numpy.org/doc/stable/reference/routines.array-creation.html
numpy.randomでランダムサンプリングをする。
numpy.random.randは0から1でのランダムサンプリング
numpy.random.chisquareはカイ二乗分布のランダムサンプリング(サンプリングする範囲や分布のパラメータ、サンプルサイズは引数に指定したりする)
numpy.random.normalはガウス分布(正規分布)からのランダムサンプリング。
https://numpy.org/doc/stable/reference/random/generated/numpy.random.rand.html